게시판 페이지네이션 성능 최적화 하기
시작하기 앞서
게시판 서비스의 핵심 기능은 CRUD입니다.
그중에서도 읽기 작업의 비중이 쓰기 작업보다 많습니다.
사용자 편의성을 위해 제공하는 페이징 기능은 보통 OFFSET 기반으로 구현되곤 합니다.
그러나 OFFSET은 데이터를 읽고 버리기 때문에 데이터가 많아질수록 슬로우쿼리를 만듭니다.
이 글에서는 페이지 매김 번호를 유지하며 느린 OFFSET을 빠르게 하기 위한 3가지 방법을 단계적으로 소개합니다.
OFFSET 방식 페이징
그 전에 먼저 OFFSET 기반 페이징부터 살펴보겠습니다.
보통의 경우 페이징을 구현하기 위해 아래와 같은 OFFSET 방식을 많이 사용합니다.
빠르게 구현할 수 있고 간단합니다.
SELECT * FROM post ORDER BY id DESC OFFSET 1000 LIMIT 20;
위 SQL문은 소규모 게시판에선 문제가 되지 않습니다.
그러나 게시글이 무수히 많이 쌓이게 되면 조회가 느려지고 이는 사용자 경험에 안좋은 영향을 줍니다.
SELECT * FROM post ORDER BY id DESC OFFSET 10000000 LIMIT 20;
특히 위와 같이 OFFSET이 커질 때, 즉 끝 페이지를 탐색할 때 가장 느려집니다.
그 이유는 OFFSET이 결과를 만들기 위해 필요 없는 데이터를 읽고 버리기 때문입니다.
1.클러스터드 인덱스 조인
※실행 결과 값은 버퍼풀에 캐싱 되어있는 기준입니다.※
우선 느린 OFFSET 쿼리와 실행계획을 살펴보겠습니다.
SELECT * FROM post ORDER BY id desc OFFSET 999950 LIMIT 50
-> Limit/Offset: 50/999500 row(s) (cost=1.06e+6 rows=50) (actual time=2799..2799 rows=50 loops=1)
-> Index scan on post using PRIMARY (reverse) (cost=1.06e+6 rows=999550) (actual time=0.0245..2708 rows=999550 loops=1)
Limit/Offset을 보면 실제 실행시간은 거의 없습니다.
그러나 버리기 위해 Index scan을 해야하는데 이 실행시간이 약 2.8s 입니다.
SELECT p.* FROM
(SELECT id FROM post ORDER BY id DESC OFFSET 999950 LIMIT 50) AS sub
JOIN post AS p ON sub.id = p.id;
위 SQL은 기존의 느린 OFFSET을 개선할 수 있습니다.
그 이유는 서브쿼리 절의 지연된 조인 덕분입니다.
실행계획을 살펴보겠습니다.
-> Nested loop inner join (cost=1.84e+6 rows=50) (actual time=1023..1023 rows=50 loops=1)
-> Table scan on t (cost=931019..931022 rows=50) (actual time=1023..1023 rows=50 loops=1)
-> Materialize (cost=931018..931018 rows=50) (actual time=1023..1023 rows=50 loops=1)
-> Limit/Offset: 50/999950 row(s) (cost=931013 rows=50) (actual time=1023..1023 rows=50 loops=1)
-> Covering index scan on post using PRIMARY (reverse) (cost=931013 rows=1e+6) (actual time=0.0627..978 rows=1e+6 loops=1)
-> Single-row index lookup on p using PRIMARY (id=t.id) (cost=0.906 rows=1) (actual time=0.00285..0.00287 rows=1 loops=50)
위 쿼리는 1s로 단축되었습니다.
Covering index scan on이 기존 느린 쿼리의 Index scan on와 실행시간 차이가 있습니다.
서브쿼리 조인이 더 빠른 이유는 기존 쿼리는 50개의 게시글을 가져오기 위해 버려지는 약 99만개의 행에 대해서도 제목, 본문 등을 메모리로 불러오는 불필요한 작업을 수행하여 느렸습니다.
특히 post 테이블에는 게시글 본문 내용인 content 컬럼이 매우 크다면 별도의 페이지에 저장되고, 이로 인해 IO 작업이 한번 더 필요하게 됩니다.
결과적으로 지연된 조인 덕분에 불필요한 IO작업을 서브쿼리 실행 이후로 미룰 수 있어 실행시간을 단축할 수 있었습니다.
2.세컨더리 인덱스 조인
클러스터드 인덱스 조인으로 느린 쿼리를 최적화 하였지만, 그럼에도 불구하고 데이터가 많아지면 다시 실행시간이 느려질 수 있습니다.
이 경우엔 아래와 같은 인덱스를 추가해주면 됩니다.
ALTER TABLE post ADD INDEX idx_id (id)
그리고 실행계획을 살펴보겠습니다.
-> Nested loop inner join (cost=1.84e+6 rows=50) (actual time=117..117 rows=50 loops=1)
-> Table scan on t (cost=931019..931022 rows=50) (actual time=117..117 rows=50 loops=1)
-> Materialize (cost=931018..931018 rows=50) (actual time=117..117 rows=50 loops=1)
-> Limit/Offset: 50/999950 row(s) (cost=931013 rows=50) (actual time=117..117 rows=50 loops=1)
-> Covering index scan on post using idx_id (cost=931013 rows=1e+6) (actual time=0.0283..96.6 rows=1e+6 loops=1)
-> Single-row index lookup on p using PRIMARY (id=t.id) (cost=0.906 rows=1) (actual time=0.00216..0.00218 rows=1 loops=50)
SQL문은 클러스터드 인덱스 조인 방식과 같았지만, 실행 계획에서는 PRIMARY 대신 idx_id 인덱스를 사용하였습니다. 그 결과 실행시간이 더 단축된 0.1s로 개선되었습니다.
idx_id 세컨더리 인덱스는 클러스터드 인덱스와 큰 차이가 있기 때문입니다.
MYSQL의 페이지 크기는 기본이 16KB 입니다.
클러스터드 인덱스는 이 페이지에 PK + 데이터 형태로 행이 저장되는데, 세컨더리 인덱스는 PK값만 저장하고 있기 때문에 클러스터드 인덱스보다 더 많은 PK를 담을 수 있습니다.
따라서 세컨더리 인덱스가 클러스터드 인덱스보다 더 적은 IO 접근으로 인해 빠릅니다.
3.OFFSET/CURSOR 혼합 페이징
세컨더리 인덱스로 최적화를 하였지만 100만 데이터가 아니라 1000만 데이터면
간단히 계산해봐도 100만개를 읽는데 0.1s가 걸렸으니 1000만개는 1s가 됩니다.
이와 같이 OFFSET 방식은 데이터가 많아지면 인덱스 추가만으로 해결이 되지 않습니다.
이 경우 커서기반 페이징으로 변경하면 되지만 페이지 매김 번호를 제공하는 것이 제한적입니다.
그래서 읽기 성능을 일관되게 보장하면서 페이지 매김 번호까지 제공하는 OFFSET과 CURSOR를 혼합한 방식을 소개하겠습니다.
우선 이 혼합 방식은 빠른 조회를 위해 게시글 작성 및 삭제시 page_chunk 테이블에 메타데이터를 미리 계산하는데 이 과정을 먼저 알아보겠습니다.
게시글 INSERT
//PostService.java
@Transactional
public PostResponse createPost(PostCreationRequest request, Long postSeq) {
Board boardProxy = entityManager.getReference(Board.class, request.boardId());
String encodedPassword = encoder.encode(request.password());
PostCreationCommand command = PostCreationCommand.of(request, boardProxy, postSeq, encodedPassword);
Post post = PostMapper.toModel(command);
Post saved = postRepository.save(post);
// 페이지 메타데이터 계산하기
int pageNo = pageChunkService.calculatePageNo(saved.getPostSeq());
pageChunkRepository.increaseInsertCount(request.boardId(), pageNo);
return PostMapper.toDto(saved);
}
게시글 저장시 pageChunkService와 pageChunkRepository를 호출하여 메타데이터를 미리 계산합니다.
PageNo 얻기
//PageChunkService.java
/*절대 변하면 안되는 상수*/
private static final int PAGE_CHUNK_SIZE = 100_000;
public int calculatePageNo(Long postId) {
int pageNo = (int) ((postId - 1) / (long) PAGE_CHUNK_SIZE) + 1;
return pageNo;
}
위 메서드는 새로운 게시글이 저장될 때 고유 ID인 postId를 받아 해당 게시글이 몇 번째 페이지인지 반환합니다.
postId가 1~100,000이면 pageNo는 1
postId가 100,001~200,000이면 pageNo는 2가 됩니다.
UPSERT를 사용하여 게시글 미리 세기
//increaseInsertCount()
INSERT INTO page_chunk (insert_count, board_id, page_no)
VALUES (1,:boardId, :pageNo)
ON DUPLICATE KEY UPDATE insert_count = insert_count + 1"
calculatePageNo메서드를 통해 반환된 pageNo를 UPSERT를 이용하여 새로운 페이지를 추가하거나
이미 존재하면 insert_count를 1 증가시킵니다.
page_chunk 테이블엔 UNIQUE INDEX (board_id, page_no)가 있습니다.
덕분에 board_id와 page_no가 같은경우 동일한 행에 PAGE_CHUNK_SIZE크기 만큼 insert_count를 증가시킵니다.
위 작업을 통해 게시글이 저장될 때마다 게시글 개수를 미리 알 수 있게되었습니다.
게시글 DELETE
// PostService.java
@Transactional
public boolean deletePost(Long boardId, Long postSeq, String rawPassword) {
Post post = postRepository.getPost(boardId, postSeq, LockModeType.PESSIMISTIC_WRITE).orElseThrow();
if (encoder.matches(rawPassword, post.getPassword())) {
post.deletePost();
// 페이지 메타데이터 계산하기
int pageNo = pageChunkService.calculatePageNo(post.getPostSeq());
int updatedRows = pageChunkRepository.increaseDeleteCount(boardId, pageNo);
return true;
}
return false;
}
게시글 INSERT처럼 삭제시에도 페이지메타데이터를 계산합니다.
위 로직에서 삭제시 쓰기 락을 거는데, 이는 getPost 메서드 호출 시 내부적으로 visible이 true인 경우만 읽도록 하여 동시에 다른 트랜잭션이 삭제시increaseDeleteCount의 값이 오염되지 않도록 방지합니다.
delete_count 증가시키기
//increaseDeleteCount()
UPDATE PageChunk pc SET pc.deleteCount = pc.deleteCount + 1
WHERE pc.board = :boardId AND pc.pageNo = :pageNo
게시글 리스트 SELECT
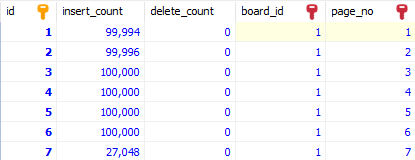
게시글 쓰기, 삭제 시 page_chunk테이블에는 위 이미지와 같이 메타데이터가 쌓이게 됩니다.
페이징서비스
// PostService.java
@Transactional(readOnly = true)
public Page<PostResponse> getPostList(Long boardId, Pageable pageable) {
//1. 게시판의 lastId를 얻기 위해 조회합니다.
Board board = boardRepository.findById(boardId).orElseThrow(NoSuchBoardIdException::new);
Long lastId = board.getPostSeq();
//2. 클라이언트가 요청한 페이지 이전의 게시글 수를 구합니다.
long postSkipOffset = pageChunkService.calculatePostSkipOffset(pageable);
//3. page_chunk 테이블의 메타데이터를 얻습니다.
PageChunkCursor pageChunkCursor = pageChunkRepository.getPostOffset(boardId, postSkipOffset).orElse(new PageChunkCursor());
//4. cursor와 offset을 계산하여 얻습니다.
long cursor = pageChunkService.calculateCursor(lastId, pageChunkCursor);
long offset = pageChunkService.calculateOffset(pageable, pageChunkCursor);
//5. 페이징 처리
Page<Post> postPage = postRepository.findAllByBoardId(boardId, cursor, pageable, offset);
return postPage.map(PostMapper::toDto);
}
calculatePostSkipOffset
public long calculatePostSkipOffset(Pageable pageable){
return (long) pageable.getPageNumber() * pageable.getPageSize();
}
클라이언트가 요청한 페이지 이전의 게시글 수를 구합니다.
만약 클라이언트가 101번째 페이지를 요청했고, 한 페이지당 보여줄 게시글이 20개라면
100 * 20 = 2000을 반환합니다.
getPostOffset
SELECT sub.page_no , sub.post_count
FROM (
SELECT
pc.page_no,
SUM(pc.insert_count - pc.delete_count) OVER (ORDER BY pc.page_no DESC) AS post_count
FROM page_chunk pc
WHERE pc.board_id = :boardId
) AS sub
WHERE sub.post_count <= :postSkipOffset
ORDER BY sub.post_count DESC
LIMIT 1
page_no: 게시글 누적합을 구하며 WHERE post_count <= :postSkipOffset 조건에 만족하는 직전 페이지 번호
post_count: WHERE post_count <= :postSkipOffset 조건에 만족하는 삽입에서 삭제를 뺀 누적합
calculateCursor
public long calculateCursor(Long lastId, PageChunkCursor pageChunkCursor) {
int beforePageNo = pageChunkCursor.getPageNo();
return (beforePageNo == 0) ? lastId : (beforePageNo - 1) * (long) PAGE_CHUNK_SIZE;
}
getPostOffset을 통해 반환받은 beforePageNo에서 1을 빼고 PAGE_CHUNK_SIZE만큼 곱하면 CURSOR를 얻을 수 있습니다.
calculateOffset
public long calculateOffset(Pageable pageable, PageChunkCursor pageChunkCursor) {
int pageNumber = pageable.getPageNumber();
int pageSize = pageable.getPageSize();
long postCount = pageChunkCursor.getPostCount();
return (long) pageNumber * pageSize - postCount;
}
클라이언트가 요청한 페이지 직전 게시글 개수에서 page_chunk로 부터 얻어온 누적합 post_count를 빼면 OFFSET을 얻을 수 있습니다.
findAllByBoardId
@Query(value = """
SELECT p.* FROM post p
INNER JOIN (SELECT board_id, post_seq FROM post
WHERE board_id = :boardId AND post_seq <= :cursor AND visible = 1
ORDER BY post_seq DESC LIMIT :#{#pageable.pageSize} OFFSET :offset) AS sub
ON p.post_seq = sub.post_seq AND p.board_id = sub.board_id
ORDER BY p.post_seq DESC
""",
countQuery = "SELECT SUM(pc.insert_count - pc.delete_count)
FROM page_chunk pc WHERE pc.board_id = :boardId",
nativeQuery = true)
Page<Post> findAllByBoardId(@Param("boardId") Long boardId,@Param("cursor") Long cursor, Pageable pageable,@Param("offset") Long offset);
OFFSET과 CURSOR를 혼합한 SQL문 입니다.
서브쿼리 절에서 :cursor를 통해 빠르게 시작지점을 찾기 때문에 큰 OFFSET으로 인한 병목을 제거합니다. :cursor만 갖고 정확한 위치를 찾을 수 없기 때문에 :offset을 통해 보정합니다.
Page객체 사용시 countQuery를 요구하는데 만약 SELECT COUNT(*) FROM post WHERE board_id = :boardId와 같이 작성했고 대용량 게시글이라면 클라이언트 요청마다 카운트 쿼리가 병목이 됩니다.
그러나 page_chunk테이블에 게시글 삽입, 삭제에 대해 미리 계산된 메타데이터가 있어 빠르게 전체 게시글 수를 얻을 수 있습니다.
약 270만개의 더미데이터 기준 적용 전/후 차이는 다음과 같습니다.


결론
OFFSET/CURSOR 혼합 페이징 방식은 읽기 성능 면에서는 OFFSET만 사용하는 것보다 매우 뛰어나지만 구현이 복잡합니다. 또한 게시글 작성 시 UPSERT문 때문에 쓰기 성능을 일부 포기해야 합니다.
사용자에게 페이지 매김 번호를 반드시 제공해야 하고 대용량 데이터가 있는 특수한 상황이면 고려해 볼 법한 방법이라고 생각합니다.
긴 글 읽어주셔서 감사합니다.
![[MySQL] 조회 쿼리에서 FOR UPDATE 쓰기잠금 실험](/content/images/size/w960/2024/10/RealMysql-BOOK.jpg)